LCA and Binary Lifting
How to jump up a tree in powers of two — kth ancestors, lowest common ancestors, and path distances, all in O(log n) per query.
if you solve enough tree problems you keep running into the same two questions — “what is the kth ancestor of this node?” and “where do the paths from u and v meet?”. both get answered by the same trick: binary lifting. this post builds it from scratch, ending with the exact template I use in contests.
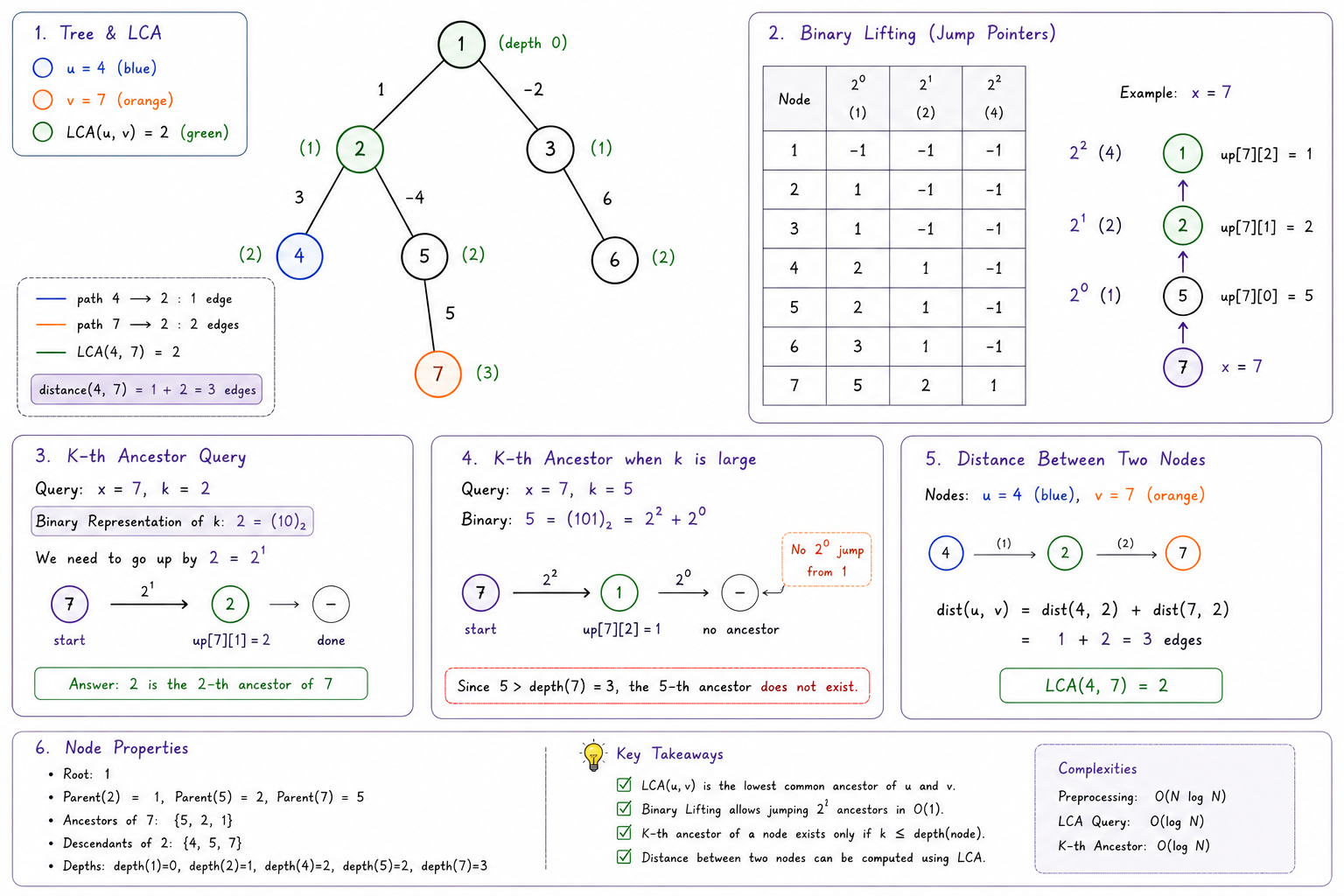
What is the LCA?
take a rooted tree. the lowest common ancestor (LCA) of two nodes u and v is the deepest node that is an ancestor of both. if you walk from u up to the root and from v up to the root, the two walks eventually merge — the LCA is the first node where they merge.
a couple of quick facts:
- if
uis an ancestor ofv, thenlca(u, v) = u lca(u, u) = u- the path from
utovalways goesu → lca → v, which is why so many path queries reduce to an lca query
The naive way
to find lca(u, v) by hand you would do this:
- whichever node is deeper, walk it up one parent at a time until both are at the same depth
- now move both up together, one step at a time, until they land on the same node
that’s correct, but it’s O(n) per query — on a long chain the walk can cross the whole tree. with 10^5 queries on a tree of 10^5 nodes that’s 10^10 steps. too slow. we need to walk up the tree faster than one step at a time.
The core idea
here’s the trick: every number has a binary representation.
13 = 8 + 4 + 1 = 2^3 + 2^2 + 2^0so jumping 13 steps up doesn’t have to be 13 single steps — it can be one jump of 8, one jump of 4, one jump of 1. if we precompute, for every node, its 1st, 2nd, 4th, 8th, … ancestors, then any jump of size k becomes at most log(k) jumps. that’s the whole “binary lifting” idea — we lift through the tree in powers of two.
so we build a table:
up[i][j] = the 2^i-th ancestor of node jup[0][j] is just the parent of j, which a single dfs gives us (along with depth[j]). every higher row comes from a really clean recurrence:
up[i][j] = up[i-1][ up[i-1][j] ]in words — to jump 2^i steps, jump 2^(i-1) steps, then jump 2^(i-1) steps again from where you landed. the table has log(n) rows of n entries, so preprocessing is O(n log n) time and space.
Kth ancestor
once the table exists, the kth ancestor is exactly the binary decomposition idea:
int kthAnc (int u, int k) {
if (k > depth[u])
return -1;
for (int i = 0; i < lg; i++)
if (k >> i & 1)
u = up[i][u];
return u;
}look at each set bit of k and take that jump. for k = 13 we jump 2^0, then 2^2, then 2^3. order doesn’t matter — the ancestors compose either way. O(log k) per query.
The LCA query
now the main event. finding lca(u, v) is the naive algorithm again, just with big jumps:
step 1 — equalize depths. assume u is the deeper one (swap otherwise). we need to lift u by exactly depth[u] - depth[v] steps. instead of computing the difference and decomposing it, the loop below does the same thing greedily — take any power-of-two jump that doesn’t overshoot v’s depth:
for (int i = lg - 1; i >= 0; i--)
if (depth[u] - (1 << i) >= depth[v])
u = up[i][u];step 2 — early exit. if u == v now, then v was an ancestor of u all along, and the answer is v itself.
step 3 — lift both together. this is the clever part. we go from the biggest jump down to the smallest, and take a jump only if it keeps u and v different:
for (int i = lg - 1; i >= 0; i--)
if (up[i][u] != up[i][v]) {
u = up[i][u];
v = up[i][v];
}
return up[0][u];why “only if they stay different”? because if up[i][u] == up[i][v], that node is a common ancestor — but maybe not the lowest one. we might have jumped past the lca. by refusing every jump that makes them equal, both nodes converge to just below the lca — they end up as two different children of it. one final parent step (up[0][u]) gives the answer.
it’s the same idea as binary searching for the boundary: instead of looking for the first place they’re equal, we push as far as possible while they’re still different.
each step is at most log(n) jumps, so a query is O(log n).
Distance between two nodes
this one falls out for free, and honestly it’s the form I use most often:
dist(u, v) = depth[u] + depth[v] - 2 * depth[lca(u, v)]depth counts edges from the root. going u → lca takes depth[u] - depth[lca] edges, going lca → v takes depth[v] - depth[lca], add them up.
Complexity
- Preprocessing: O(n log n) time and space — one dfs plus filling the table
- Per query: O(log n) for
lca,dist, andkthAnc
one note — cp-algorithms presents a slightly different version that stores euler tour entry/exit times (tin/tout) and uses them for O(1) “is u an ancestor of v” checks instead of depths. both versions are equivalent in complexity; I find the depth-based one easier to remember since the depth array is useful on its own (it gives you dist for free).
I used this exact template recently in 3559. Number of Ways to Assign Edge Weights II — the whole problem collapses to dist(u, v) once you see the counting argument.
Full Template
BinaryLift — full copy-paste template
#include <bits/stdc++.h>
using namespace std;
struct BinaryLift {
int n, lg;
vector<int> depth;
vector<vector<int>> adj, up;
BinaryLift(int _n)
: n(_n), lg(__lg(n - 1) + 1),
depth(n), adj(n),
up(lg, vector<int>(n, 0)) {}
void addEdge(int u, int v) {
adj[u].push_back(v);
adj[v].push_back(u);
}
void init(int r = -1) {
if (r == -1) {
for (int u = 0; u < n; u++)
if (up[0][u] == -1) dfs(u);
} else {
dfs(r);
}
for (int i = 1; i < lg; i++)
for (int j = 0; j < n; j++)
if (up[i - 1][j] != -1)
up[i][j] = up[i - 1][up[i - 1][j]];
}
void dfs(int u) {
for (int v : adj[u])
if (v != up[0][u]) {
depth[v] = depth[u] + 1;
up[0][v] = u;
dfs(v);
}
}
// lowest common ancestor
int lca(int u, int v) {
if (depth[u] < depth[v]) swap(u, v);
for (int i = lg - 1; i >= 0; i--)
if (depth[u] - (1 << i) >= depth[v])
u = up[i][u];
if (u == v) return u;
for (int i = lg - 1; i >= 0; i--)
if (up[i][u] != up[i][v]) {
u = up[i][u];
v = up[i][v];
}
return up[0][u];
}
// number of edges on the path u..v
int dist(int u, int v) {
return depth[u] + depth[v] - 2 * depth[lca(u, v)];
}
// k-th ancestor of u, or -1 if it doesn't exist
int kthAnc(int u, int k) {
if (k > depth[u]) return -1;
for (int i = 0; i < lg; i++)
if (k >> i & 1) u = up[i][u];
return u;
}
};
// --- usage ---
// BinaryLift g(n + 1); // 1-indexed, size n+1
// for (auto& e : edges)
// g.addEdge(e[0], e[1]);
// g.init(1); // root = 1
//
// g.lca(u, v)
// g.dist(u, v)
// g.kthAnc(u, k)BinaryLift with path sum — weighted edges
#include <bits/stdc++.h>
using namespace std;
struct BinaryLift {
int n, lg;
vector<int> depth;
vector<vector<pair<int,int>>> adj;
vector<vector<int>> up;
vector<vector<long long>> sum;
BinaryLift(int n) : n(n), lg(__lg(n) + 1),
depth(n, 0), adj(n),
up(lg, vector<int>(n, -1)),
sum(lg, vector<long long>(n, 0)) {}
void addEdge(int u, int v, int w) {
adj[u].push_back({v, w});
adj[v].push_back({u, w});
}
void dfs(int u, int p, int w) {
up[0][u] = p;
sum[0][u] = w;
for (auto [v, wt] : adj[u]) {
if (v == p) continue;
depth[v] = depth[u] + 1;
dfs(v, u, wt);
}
}
void init(int root = 0) {
dfs(root, -1, 0);
for (int i = 1; i < lg; i++)
for (int v = 0; v < n; v++) {
int mid = up[i-1][v];
if (mid == -1) continue;
up[i][v] = up[i-1][mid];
sum[i][v] = sum[i-1][v] + sum[i-1][mid];
}
}
int lca(int u, int v) {
if (depth[u] < depth[v]) swap(u, v);
int diff = depth[u] - depth[v];
for (int i = 0; i < lg; i++)
if (diff >> i & 1) u = up[i][u];
if (u == v) return u;
for (int i = lg - 1; i >= 0; i--)
if (up[i][u] != up[i][v]) {
u = up[i][u];
v = up[i][v];
}
return up[0][u];
}
// sum of edge weights climbing k steps from u
long long liftSum(int u, int k) {
long long res = 0;
for (int i = 0; i < lg; i++)
if (k >> i & 1) { res += sum[i][u]; u = up[i][u]; }
return res;
}
// total weight on path u..v
long long pathSum(int u, int v) {
int L = lca(u, v);
return liftSum(u, depth[u] - depth[L])
+ liftSum(v, depth[v] - depth[L]);
}
int dist(int u, int v) {
return depth[u] + depth[v] - 2 * depth[lca(u, v)];
}
int kthAncestor(int u, int k) {
for (int i = 0; i < lg; i++)
if (k >> i & 1) u = up[i][u];
return u;
}
};
// --- usage ---
// BinaryLift g(n);
// g.addEdge(u, v, w);
// g.init(0); // root = 0
//
// g.lca(u, v)
// g.pathSum(u, v) // sum of weights on u..v
// g.dist(u, v) // number of edges on u..v
// g.kthAncestor(u, k)